VIỆN CÔNG NGHỆ VÀ ĐÀO TẠO DEVMASTER
Đào tạo - Phần mềm - Cho thuê nhân sự
VIỆN CÔNG NGHỆ VÀ ĐÀO TẠO DEVMASTER
Đào tạo - Phần mềm - Cho thuê nhân sự

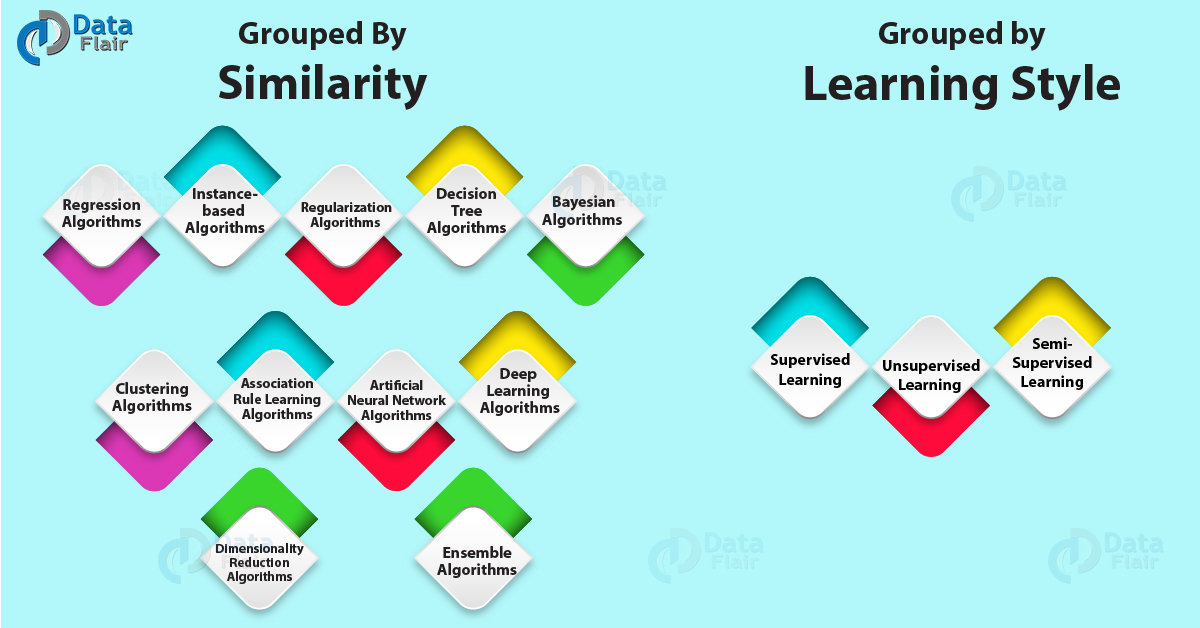
Có hai cách để phân loại các thuật toán Machine Learning mà bạn có thể gặp qua.
Nói chung, cả hai cách này đều hữu ích. Tuy nhiên, trong bài viết này, tôi sẽ tập trung vào việc phân loại các nhóm thuật toán theo sự giống nhau và phân tích sâu hơn vào từng loại
Có nhiều cách khác nhau mà thuật toán có thể mô hình hóa một vấn đề vì nó liên quan đến sự tương tác với trải nghiệm. Nói cách khác, bạn sẽ cần phải xác định được phong cách học tập của một thuật toán. Thật may là chỉ có một vài kiểu học tập chính mà thuật toán Machine Learning có thể có. Do đó mà bạn phải suy nghĩ kĩ về vai trò của dữ liệu input và quá trình chuẩn bị môi trường cho thuật toán học tập để có được kết quả tốt nhất.
Sau đây, chúng ta hãy xem xét ba phong cách học tập khác nhau trong thuật toán Machine Learning:
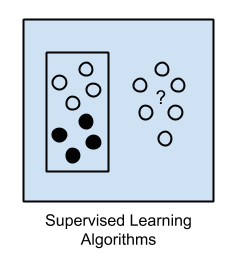
Về cơ bản, trong thuật toán machine Learning có giám sát này, input data được gọi là dữ liệu huấn luyện với kết quả đã biết tại một thời điểm. Trong đó, một mô hình được chuẩn bị thông qua một quá trình đào tạo để yêu cầu các thuật toán này đưa ra dự đoán. Những dự đoán sai sẽ ngay lập tức được thông báo để chỉnh sửa. Như vậy, quá trình đào tạo sẽ tiếp tục cho đến khi mô hình đạt được mức hoàn thiện mong muốn.
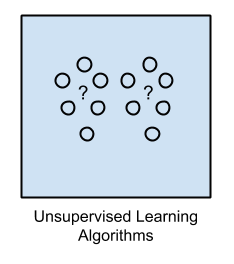
Trong thuật toán machine learning không giám sát này, input data đều không được dán nhãn và không có kết quả rõ ràng. Vì vậy, chúng ta phải chuẩn bị mô hình bằng cách suy đoán các cấu trúc có trong input data. Điều này có thể là trích xuất các quy tắc chung. Nó có thể là thông qua một quá trình toán học để giảm sự sai lệch và lỗi.
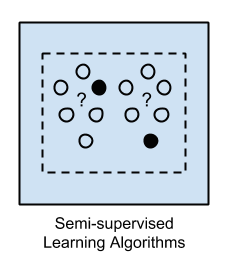
Input data là một hỗn hợp của các dữ liệu được gắn nhãn và không gắn nhãn. Trong đó chúng ta có đặt ra một kết quả và mục tiêu theo mong muốn. Nhưng mô hình thuật toán cần phải học các cấu trúc để tổ chức dữ liệu cũng như đưa ra các dự đoán.
Thuật toán ML thường được chia nhóm tùy theo sự giống nhau về chức năng của chúng. Ví dụ, phương pháp cây quyết định (decision tree) và phương pháp lấy cảm hứng từ mạng thần kinh. Tôi nghĩ đây là cách hữu ích nhất để phân chia nhóm các thuật toán machine learning và đó cũng là cách tiếp cận chúng ta sẽ sử dụng ở đây.
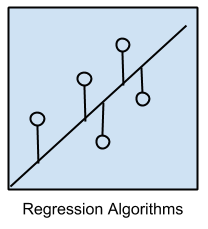
Thuật toán hồi quy có liên quan mật thiết với việc mô hình hóa mối quan hệ giữa các biến, mà ta có thể tinh chỉnh bằng cách sử dụng một thước đo tần suất các lỗi xuất hiện trong dự đoán được thực hiện bởi thuật toán machine learning.
Những phương pháp này là có liên quan mật thiết tới thống kê và statistical machine learning. Điều này có thể gây nhầm lẫn bởi vì chúng ta có thể sử dụng hồi quy để tham khảo class của bài toán và class của thuật toán. Thuật toán hồi quy phổ biến nhất là:
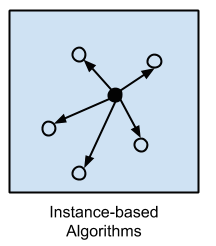
Mô hình này sử dụng dữ liệu đào tạo cá thể để giải quyết vấn đề và đưa ra quyết định được coi là quan trọng hoặc cần thiết. Phương pháp này sẽ cho ra một database để nó có thể so sánh dữ liệu mới.
Vì lý do này, bạn có thể xem phương thức chọn tất cả những kẻ chiến chiến thắng và học tập dựa trên thông tin từ bộ nhớ. Các thuật toán dựa trên cá thể phổ biến nhất là:
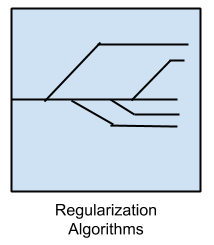
Một phần mở rộng được thực hiện cho một phương pháp khác. Chỉ thích hợp với các mô hình đơn giản. Tôi nhắc tới các thuật toán chuẩn hóa ở đây vì chúng rất phổ biến, mạnh mẽ và thường là những sửa đổi đơn giản được thực hiện cho các phương pháp khác. Các thuật toán phổ biến nhất là:
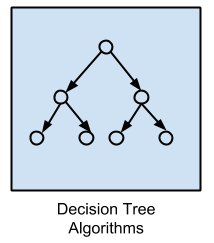
Như cái tên, đây là phương pháp xây dựng một mô hình đưa ra quyết định. Điều đó được thực hiện dựa trên những giá trị của các thuộc tính trong dữ liệu. Phương pháp cây quyết định được đào tạo về dữ liệu của các vấn đề phân loại và hồi quy. Đây là phương pháp rất nhanh chóng và chính xác nên nhận được rất nhiều quan tâm trong cộng đồng machine learning. Một số thuật toán cây quyết định phổ biến nhất bao gồm:
(Hết phần 1)
Nguồn: Sưu tầm từ internet via dzone










")
 - FullStack")

.png "Lập trình frontend với reacjs (Full)")

