VIỆN CÔNG NGHỆ VÀ ĐÀO TẠO DEVMASTER
Đào tạo - Phần mềm - Cho thuê nhân sự
VIỆN CÔNG NGHỆ VÀ ĐÀO TẠO DEVMASTER
Đào tạo - Phần mềm - Cho thuê nhân sự

Dataset Acquisition for Deep Learning
Computer Vision (CV) là một ngành khoa học với mục đích giúp cho máy tính nhận dạng, hiểu và xử lý được các dữ liệu hình ảnh, video từ đó trích xuất được các thông tin và dữ liệu theo yêu cầu. CV đã có những bước tiến lớn lao nhờ vào Deep Learning, IoT và Cloud Computing, các models ngày nay đã có độ chính xác và tính tin cậy khá cao trong nhiều bài toán như phân loại ảnh (classification), nhận diện khoanh vùng đối tượng (object detection), phân vùng đối tượng (segmentation) và các bài toán về sinh ảnh (generation). Đây là tiền đề để xây dựng và phát triển các ứng dụng AI về sau.
Về cơ bản thì các bước để giải quyết một bài toán Deep Learning trong CV như sau:
1. Thu thập dữ liệu cho bài toán. (Collecting Dataset)
2. Các bài toán trong CV đa phần là Supervised Learning nên cần đánh nhãn dữ liệu thu thập được (Labeling Dataset).
3. Chọn các Deep Learning models phù hợp với bài toán-> Tiến hành training -> Tiến hành kiểm thử và đánh giá (Test and Evaluate Model)
4. Lặp lại các bước trên cho đến khi thỏa mãn yêu cầu của bài toán (Satisfying acceptable quality).
Chúng ta đa số đều chú tâm tới bước 3 của bài toán, tức là ở bước chọn các models và các phương pháp cải thiện model hyperparameters (dựa vào metrics, optimizers, activation functions…) mục đích nhằm đạt được error rate thấp nhất (finding a better algorithm to make a better decisions).
Một điều quan trọng thường bỏ qua khi bắt đầu một bài toán CV Deep Learning là bước thu thập dữ liệu để training cho model. Ví dụ đơn giản là các labeled-trainning images (ngoài image thì còn có videos, 3D point cloud) cho các bài toán binary, multiclass, hay multi-label classification, tức là tìm một tập các bức ảnh đã được đánh nhãn thuộc các classes khác nhau (ví dụ các nhãn như chó, mèo, gà v.v…). Đa phần trong quá trình học CV hay Deep Learning, chúng ta làm việc trên những dataset thu sẵn đã được đánh nhãn. Nhưng thực tế, tùy thuộc vào bài toán mà cần thu thập dữ liệu khác nhau và ít khi tương quan với những dataset sẵn có!
Các Deep Learning models không thể hoạt động nếu thiếu data, trường hợp dataset quá nhỏ thì dể dẫn đến overfitting và model không thể học được đầy đủ các features cho các trường hợp tổng quan hay nói khác đi là model thiếu khả năng tổng quan hóa — generalization. Một cách khác là dùng data augmentation cho existing training data, nhưng vấn đề là các generated images ít nhiều đã được “remix” từ các pixels sẵn có (still inter-correlated) do đó model cũng khó thoát khỏi overfitting (cần áp dụng thêm nhiều phương pháp khác như weight decay, dropout…). Vậy làm sao để tìm “đủ” training data và đánh nhãn cho nó? Có thể nói đây là công việc mất nhiều công sức nhất trong CV Deep Learning — an expensive task! Trong bài viết này mình sẽ đề cập tới một số kỹ thuật tìm và collect một bộ training dataset đủ “ngon” để các bạn có thể tiến hành training và kiểm thử model của mình. Ngoài ra mình sẽ nói qua về một dataset rất phổ biến trong cộng đồng Deep Learning, đó là ImageNet.
Lưu ý: Thu thập dữ liệu xong thì cần tiến hành tiền xử lí vì hầu như dữ liệu thu thập được đều là dữ liệu thô (raw data) với height, width, ratio… khác nhau nên không thể đưa thẳng vào Deep Learning Models! Thường thì chúng ta sẽ sử dụng các thư việc có sẵn như OpenCV, Scikit-Image… để preprocessing image.
“Data is like garbage. You’d better know what you are going to do with it before you collect it.” — Mark Twain
Bước 1: Thu thập dữ liệu (Collecting Dataset)
Trước tiên chúng ta cần phải hiểu và nắm được bài toán cần giải quyết là gì? Business value của nó để có thể tìm kiếm chính xác dữ liệu training cho bài toán! Với các bài toán classification có thể dựa vào tên các classes để tạo thành các keywords và sử dung các công cụ crawling data từ Internet cho việc tìm ảnh. Hoặc có thể tìm ảnh, videos từ các trang mạng xã hội, ảnh vệ tinh trên Google, free collected data từ camera công cộng hay xe hơi (Waymo, Tesla), thậm chí có thể mua dữ liệu từ bên thứ 3 (lưu ý tính chính xác của dữ liệu). Cũng cần phải biết đến những dataset đã được tổng hợp sẵn có thể liên quan đến bài toán của chúng ta, ở dưới là một số dataset phổ biến:
· Common Objects in Context (COCO)
· ImageNet
· KITTI
· The University of Edinburgh School of Informatics’ CVonline: Image Databases
· Yet Another Computer Vision Index To Datasets (YACVID)
· UCI Machine Learning Repository
· Udacity Self driving car datasets
· Autonomous driving dataset by Comma.ai
Bước 2: Đánh nhãn dữ liệu (Labeling data)
Đây là bước khá quan trọng vì sẽ đánh giá mô hình chúng ta làm việc tốt hay không! Đánh nhãn sai dữ liệu sẽ làm cho model dự đoán và đánh giá sai -> tốn nhiều thời gian và công sức bỏ ra cho quá trình training. Có hai vấn đề cần lưu ý là:
· Làm thế nào để đánh nhãn dữ liệu?
· Ai sẽ đánh nhãn dữ liệu?
Chúng ta sẽ lần lượt đi qua từng vấn đề!
Vấn đề 1 — Làm thế nào để đánh nhãn dữ liệu? Sau khi đã tìm được dataset cho bài toán, cần xác định xem bài toán thuộc dạng nào? Ví dụ classification, object detection, segmentation… Từ đó có thể tiến hành process data để đánh nhãn cho phù hợp! Trường hợp classification thì các labels chính là các keywords dùng trong quá trình tìm và crawling data từ Internet. Trường hợp instance segmentation cần có nhãn cho từng pixel của ảnh. Lúc này chúng ta cần phải sử dụng tools để tiến hành image annotation (tức là set label và metadata cho ảnh). Các tools phổ biến có thể kể đến là Comma Coloring, Annotorious, LabelMe… Các tool này sẽ hỗ trợ GUI cho việc đánh label từng segment của ảnh. Ví dụ:

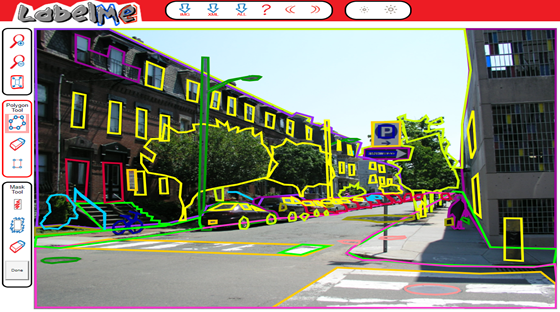
Nguồn: http://labelme.csail.mit.edu/Release3.0/
Tuy nhiên công việc này khá thủ công và tốn rất nhiều thời gian! Một cách khác nhanh hơn bằng cách sử dụng algorithms như Polygon-RNN++ (https://arxiv.org/abs/1803.09693) hay Deep Extreme Cut (https://arxiv.org/abs/1711.09081). Polygon-RNN++ nhận input là object trong image và cho ra output là các polygon points (điểm đa giác) bao quanh object để định hình các segments trong ảnh, từ đó thuận lợi hơn cho việc đánh label. Nguyên lý làm việc của Deep Extreme Cut cũng tương tự như Polygon-RNN++ nhưng với số polygon là 4. Chi tiết hơn có thể xem qua ở đây https://www.youtube.com/watch?v=evGqMnL4P3E
Ngoài ra còn có thể sử dụng phương pháp tranfer learning để đánh nhãn dữ liệu. Bằng việc sử dụng pre-trained models trên các large-scale dataset như ImageNet, Open Images. Các pre-trained models đã “học” rất nhiều features từ hàng triệu bức ảnh khác nhau nên tính chính xác khá cao. Dựa vào các models này, chúng ta có thể tìm và đánh label cho các bounding box của từng object trong ảnh. Cần lưu ý là các pre-trained models này phải có tính tương đồng với collected dataset để có thể tiến hành feature-extraction hay fine-turning.
“The snowball effect” — sau khi dùng dữ liệu trên để train model cho bài toán, chúng ta lại có thể sử dụng lại chính model này để đánh nhãn cho các dữ liệu mới.
Vấn đề 2 — Ai sẽ đánh nhãn dữ liệu? Có 2 dạng khác nhau:
In-house: chính bạn sẽ là người đánh nhãn, hoặc nhờ người thân, bạn bè giúp đỡ! Nếu dư giả hơn thì bạn có thể lập team để tiến hành đánh nhãn dữ liệu. Ưu: dễ kiểm soát tính chính xác của dữ liệu, chi phí thấp. Nhược: tốn khá nhiều thời gian cho việc collect và label data.
Out-source: nhờ bên thứ 3, có thể là các công ty và dịch vụ chuyên cung cấp data theo yêu cầu nghiệp vụ. Ưu: dữ liệu có khả năng tổng hợp nhanh. Nhược: dữ liệu cần minh bạch và có tính chính xác, tốn nhiều chi phí!
Ngoài ra chúng ta còn có thể sử dụng online workforce resources như Amazon Mechanical Turk (https://www.mturk.com/) hay Crowdflower (http://www.crowdflower.com/). Nói ngắn gọn là nhờ cộng đồng mạng đánh nhãn data giúp mình, thường thì có thu phí. Đây cũng là cách mà các big dataset như ImageNet hay Microsoft Coco ra đời. Tuy nhiên tính chính xác và cách tổ chức của dữ liệu là vấn đề mà chúng ta cần quan tâm.
Tùy theo điều kiện và yêu cầu của mỗi bài toán mà cần lựa chọn những phương án phù hợp!
Brief Introduction to ImageNet
Trong phần này mình sẽ sơ lược qua về ImageNet, bộ dữ liệu dataset rất phổ biến trong CV Deep Learning với hơn 14 triệu ảnh và hơn 20000 classes khác nhau. Những khó khăn từ lúc mới bắt đầu dự án, cách nó hình thành và ra đời để phục vụ cho CV với mục đích “We’re going to map out the entire world of objects.”
1. What is ImageNet?
ImageNet ban đầu là một project ra đời với mục đích là thu thập, đánh nhãn và phân loại các bức ảnh thành các “synset” (synonym set) khác nhau theo cấu trúc của WordNet (a large lexical database of English).
Project được bắt đầu từ năm 2006 bởi cô Fei-Fei Li — a chief scientist at Google Cloud, a professor at Stanford, and director of the university’s AI lab.
2. ImageNet Large Scale Visual Recognition Challenge (ILSVRC)
Bộ dataset nổi tiếng này được sử dụng trong các cuộc thi của Computer Vision với tên gọi là ILSVRC. Competion này được tổ chức từ năm 2010 tới 2017 (http://image-net.org/challenges/LSVRC/) với mục đích là xây dựng một model với độ chính xác cao cho bài toán image classification. Các model chiến thắng trong cuộc thi đều là các model CNN Deep Learning (AlexNet, SqueezeNet, VGGNet, GoogLeNet, ResNet, SEnet). Bộ dataset này đã trở thành một tiêu chuẩn chung (de facto standard) cho các classification algorithms trong CV và mở ra một kỷ nguyên mới cho Deep Learning.
Trong vòng 7 năm (2010–2017), the winning accuracy trên ImageNet dataset tăng từ 71.8% đén 97.3%, có thể nói đã vượt qua khả năng nhận thức của con người và tạo ra một dữ liệu đủ lớn cho các algorithms với độ chính xác cao — bigger data leads to better decisions!
3. Short history and Challenges
Những ý tưởng dầu tiên của dự án bắt đầu từ năm 2006, lúc này cô Fei-Fei Li đang là giáo sư của trường đại học Illinois Urbana-Champaign (UIUC). Trong quá trình nghiên cứu về CV, cô Li nhận thấy các models và algorithms của mình không thể hoạt động tốt khi thiếu một bộ dataset đủ lớn, đủ phản ánh các khía cạnh khác nhau của thực tại. Cô đưa ra một giải pháp là build một bộ dataset có đầy đủ tính chất như trên. “We decided we wanted to do something that was completely historically unprecedented. We’re going to map out the entire world of objects.” — cô Li nói.
Cô Li bắt tay vào dự án bằng cách tìm hiểu nhiều researchs khác nhau về cách biểu diễn data của thế giới thực. Trong quá trình đó cô đã thấy cấu trúc của WordNet phù hợp với hướng tiếp cận của mình nhất. Cô đã tìm gặp giáo sư Christiane Fellbaum (Princeton University) để bàn về cách xây dựng một hệ thống mapping images cho từng category của WordNet.
WordNet là project về xây dựng một cấu trúc phân tầng cho English (a hierarchal structure for the English language) được bắt đầu từ giữa những nãm 1980 bởi giáo sư George A. Miller (Princeton University). Các từ vựng tiếng Anh được sắp xếp giống như index của một bộ từ điển, nhưng các từ có tính chất liên hệ và phân cấp rõ ràng. Ví dụ: “dog” sẽ xếp trong lớp “canine”, và “canine” sẽ nằm trong lớp “mamal”.
Một tháng sau đó, cô Li tham gia vào dự án ở Princeton University cùng hai cộng sự là giáo sư Kai Li và trợ lý giáo sư Jia Deng. Về sau Deng thay Li tiếp tục dự án ImageNet từ năm 2017.

Nguồn: http://www.image-net.org/papers/ImageNet_2010.pdf
Ý tưởng đầu tiên của cô Li là thuê sinh viên của trường tìm ảnh từ Internet để đưa vào từng category của bộ dataset với chi phí là 10$/sinh viên. Nhưng sau vài phép tính toán học, cô Li nhận thấy dự án sẽ mất ít nhất 19 năm để hoàn thành.


Nguồn: http://www.image-net.org/papers/ImageNet_2010.pdf
Ý tưởng thuê sinh viên bị bãi bỏ, cô Li và team của mình họp bàn để tìm ra một idea khác phù hợp hơn. Ý kiến được nêu ra là sử dụng Computer Vision algorithms để tìm và phân loại các images từ Internet. Nhưng nếu sử dụng CV algorithms thì các thuật toán về sau sẽ bị giới hạn bởi chính các algorithms này và làm mất tính tổng quan. Ý tưởng về thuê sinh viên thì time-consuming, sử dụng algorithms thì không ổn, team không có đủ kinh phí, dự án tưởng chừng đi vào bế tắc — “Li said the project failed to win any of the federal grants she applied for, receiving comments on proposals that it was shameful Princeton would research this topic, and that the only strength of proposal was that Li was a woman”.
Cuối cùng cô Li đã tìm thấy giải pháp cho chính dự án của mình khi một sinh viên suggest cô sử dụng Amazon Mechanical Turk (https://www.mturk.com/) — a crowdsourcing marketplace. Chính điều này đã làm thay đổi hoàn toàn dự án ImageNet. “He showed me the website, and I can tell you literally that day I knew the ImageNet project was going to happen.” — cô Li nói. “Suddenly we found a tool that could scale, that we could not possibly dream of by hiring Princeton undergrads.”
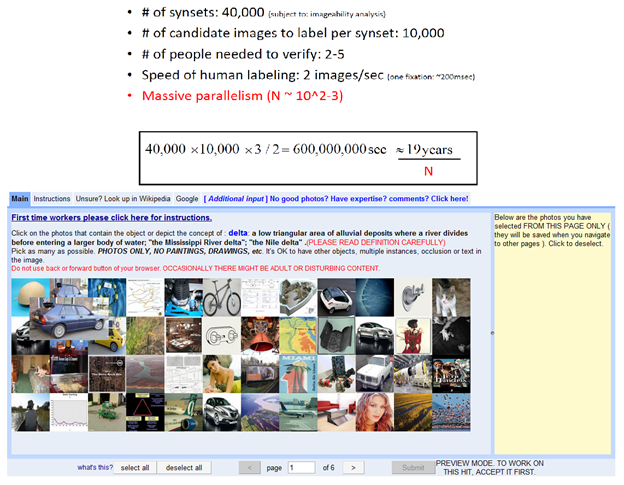
Nguồn: http://www.image-net.org/papers/ImageNet_2010.pdf
Nhưng việc sử dụng Amazon Mechanical Turk cũng mang lại những khó khăn nhất định về tính chính xác và cấu trúc của hệ thống. Đầu tiên phải thuê bao nhiêu Turkers để tìm và phân loại cho từng ảnh? Trường hợp conflict về việc xác định object trong image thì cần phải giải quyết như thế nào? Cơ chế validation cần phải build thế nào để đảm bảo tính chính xác? Trường hợp các Turkers muốn cheat và phá hoại project thì phải xử lý ra sao? Đây chỉ là một vài trong số những khó khăn mà team của Li phải đối mặt. Cô Li và các cộng sự đã đưa ra những giải pháp cho các vấn đề trên trong paper “ImageNet: A Large-Scale Hierarchical Image Database” (http://www.image-net.org/papers/imagenet_cvpr09.pdf) bằng cách xây dựng cơ chế voting, enhancements, quiz và các statistic models.
Sau khi sử dụng Amazon Mechanical Turk, dự án ImageNet đã mất khoảng 3 năm để hoàn thành. Bộ dataset ban đầu gổm 3.2 triệu ảnh, chia thành 5247 categories và 12 sub-trees như “mammal,” “vehicle,” và “furniture.” Năm 2009, cô Li và team publish the ImageNet paper “ImageNet: A Large-Scale Hierarchical Image Database” và announce research của mình ở Conference on Computer Vision and Pattern Recognition (CVPR). ImageNet và ILSVRC từ đó đã mở ra một kỷ nguyên mới cho CV và Deep Learning.
“One thing ImageNet changed in the field of AI is suddenly people realized the thankless work of making a dataset was at the core of AI research,” cô Li nói. “People really recognize the importance the dataset is front and center in the research as much as algorithms.”
Conclusion
Trong bài viết này, mình đã giới thiệu cho các bạn một số kỹ thuật để tìm và collect dataset, phục vụ cho quá trình training Deep Learning models. Cần bạn cần lưu ý về tính chính xác và cấu trúc của dataset để có thể build một model với độ chính xác cao nhất. Ngoài ra, các bạn cũng được biết thêm về ImageNet, môt bộ dataset rất phổ biến trong Deep Learning, từ idea ban đầu với cách thức mà nó được hình thành và những challenges trong quá trình build. Với những kiến thức và hiểu biết này, mình tin rằng các bạn sẽ biết cách xây dựng một good dataset để có thể tạo ra những Deep Learning models tốt nhất! Happy learning!
Devmaster Academy via Medium










")
 - FullStack")

.png "Lập trình frontend với reacjs (Full)")

